

Data-Mining and Machine Learning
Data-Mining is a process that identifies and presents patterns, structures, relationships, trends and peculiarities through the systematic application of numerical algorithms to a database of measurement or calculation. It is therefore typically used when the question is not precisely defined or the choice of a suitable statistical model for the existing data is unclear. OptiY has new and comprehensive algorithms from Machine Learning, Artificial Intelligence, Optimization, Genetic Evolution, Combinatorics, Graph Theory, Numerical Statistics, etc. This makes it possible to find and solve previously undiscovered solutions for open questions by means of extended and novel analyses that have gone beyond standardized procedures.
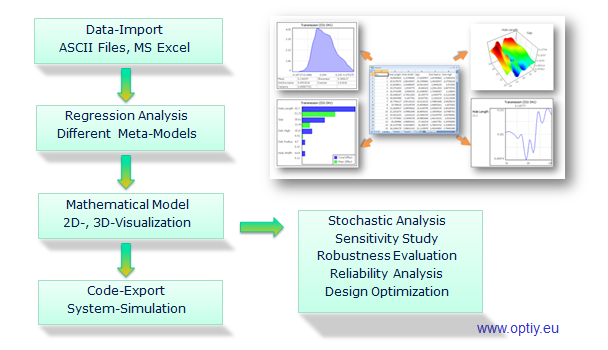
With data import/export wizard you can import or export the data in the form of ASCII text file or MS Excel file quickly and easily. If there is a data error in a certain place, a message is displayed to the user to correct it. The process chain for the analysis is automatically generated in the workflow editor. In addition, individual data processing steps can also be easily created and supplemented graphically.
After the start of the data analysis, the data visualization and statistics take place. Extensive graphical 2D and 3D elements such as histogram, correlation matrix, scatter plot, parallel chart, table, etc. are available. The operation is very easy by drag and drop with the mouse click. Statistical moments and distributions of the data can be read here. This makes possible to check the database and to detect and correct any irregularities or errors in advance. For dynamic data, OptiY can also perform a time series analysis such as time and FFT frequency analysis.
The 3 important tasks for recognizing patterns, structures and relationships include cluster analysis, regression and classification. Clustering sorts the data to different groups whose members have the same or similar properties. Regression forms an analogous mathematical function over the data in parameter space. On the other hand, Classification has the task of mapping several states of the data by using digital mathematical functions. This makes possible to recognize and represent relationships between input and output parameters in the form of metamodels. These metamodels are the basis for further derived tasks such as prediction, sensitivity studies, uncertainty analysis and optimization as well as robust design. Thus, prediction about the future trend, pattern or object recognition can also be made.
Sensitivity analysis answers questions about reducing data complexity and explaining the cause-and-effect relationship. All parts of the variations of individual input parameters on the total variation of the target parameters are statistically calculated on the basis of metamodel. This makes possible to recognize important parameters and their interactions and thus also to identify the causes of the problem.
Uncertainty analysis investigates unavoidable scattering or uncertainties of the input parameters. From this, the variation of the target parameters is calculated analytically and accurately. Thus, it is possible to investigate the variation of a process at one operating point for a specification, whether the required safety and robustness of the process is guaranteed?
Optimization looks in the parameter space for the best operating point where the objective function is best met for the user-defined requirements. All you have to do is formulate objectives and OptiY will automatically find optimal parameters. For example, it makes sense to find an optimal operating point for a process where the energy loss is the lowest.
Robust Design is an optimization of the uncertainty analysis including the parameter scattering or uncertainties. An optimal operating point for a specification is sought, in which the required safety and robustness of the process is always guaranteed despite the unavoidable parameter scattering. This advanced technology is part of the innovative core in OptiY.
With the Data-Mining Edition you can also generate the data for the design of experiments. Various methods such as Monte-Carlo, Latin-Hypercube, Sobol, Orthogonal Array, Central Composite, etc. can be used for statistical design of experiments. Correlations between the parameters or conditions for the data set can be easily mapped. Another innovation of OptiY is the adaptive design of experiments. On the basis of an existing database at the beginning, a metamodel is first formed. Further measuring points in the parameter space are proposed in order to achieve more accurate metamodels or better results of data analysis. It is the most efficient design of experiments with fewer measuring points. This saves a lot of effort, time and costs for expensive experiments.
Case Studies
