

Data-Mining und Maschinelles Lernen
Data-Mining ist ein Prozess, der durch systematische Anwendung von numerischen Algorithmen auf einen Datenbestand aus Messung oder Berechnung Muster, Strukturen, Zusammenhänge, Trends und Besonderheiten identifiziert und darstellt. Sie wird daher typischerweise eingesetzt, wenn die Fragestellung nicht genau definiert ist oder auch die Wahl eines geeigneten statistischen Modells für die vorhandenen Daten unklar ist. OptiY verfügt über neue und umfassende Algorithmen aus Maschinellen Lernen, künstlicher Intelligenz, Optimierung, Genetischen Evolution, Kombinatorik, Graphentheorie, Numerische Statistik usw. Damit ist es möglich, durch über standardisierten Verfahren hinaus erweiterte und neuartige Analysen bisher unentdeckte Lösungsmöglichkeiten für die offene Fragenstellung zu finden und zu lösen.
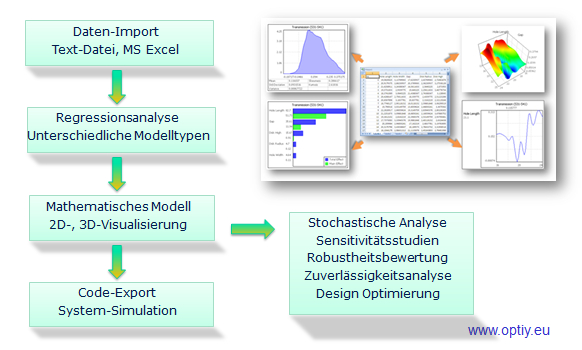
Mit Daten-Import/Export-Assistent kann man die Daten in Form von ASCII-Text-Datei oder MS Excel-Datei ganz schnell und einfach importieren oder exportieren. Wenn an bestimme Stelle ein Datenfehler vorliegt, wird dem Nutzer eine Meldung angezeigt, um es zu korrigieren. Die Prozesskette für die Analyse wird im Workflow-Editor automatisch erzeugt. Außerdem kann man auch individuelle Datenverarbeitungsschritte grafisch leicht erstellen und ergänzen.
Nach dem Start der Datenanalyse erfolgen die Datenvisualisierung und Statistik. Umfangreiche graphische 2D- und 3D-Elemente wie Histogramm, Korrelationsmatrix, Scatterplot, Parallelchart, Tabelle usw. stehen zur Verfügung. Die Bedienung ist ganz einfach per Drag und Drop mit dem Mausklick. Statistische Momente und Verteilungen der Daten lassen sich hier ablesen. Damit ist es möglich, den Datenbestand zu überprüfen und eventuelle Unregelmäßigkeiten oder Fehler vorab zu erkennen und zu korrigieren. Für dynamische Daten kann man auch in OptiY eine weitreichende Zeitreihenanalyse wie Zeit und FFT Frequenzanalyse unterziehen.
Zu den 3 wichtigen Aufgaben zur Erkennung von Muster, Strukturen und Zusammenhänge gehören Clusteranalyse, Regression und Klassifikation. Clusteranalyse sortiert die Daten nach verschiedenen Gruppen, deren Mitglieder die gleichen oder ähnlichen Eigenschaften haben. Regression bildet eine analoge mathematische Funktion über die Datenwolken im Parameterraum. Dagegen hat die Klassifikation die Aufgabe, mehrere Zustände der Datenmenge durch digitale mathematische Funktionen abzubilden. Damit ist es möglich, Zusammenhänge zwischen Parametern und Zielgrößen in Form von Metamodellen zu erkennen und darzustellen. Diese Metamodelle bilden die Grundlagen für weitere abgeleitete Aufgaben wie Vorhersage, Sensitivitätsstudien, Unsicherheitsanalyse und Optimierung sowie Robust Design. Damit kann man auch eine Vorhersage über den zukünftigen Trend, eine neue noch unbekannte Muster- bzw. Objekterkennung treffen.
Mit Sensitivitätsanalyse beantwortet man Fragen zur Reduzierung der Datenkomplexität und zur Erklärung der Ursache-Wirkungs-Beziehung. Dabei werden die Anteile der Variationen von einzelnen Parametern auf die Variation der Zielgrößen auf der Basis von Metamodell statistisch berechnet. Dadurch ist es möglich, wichtige Parameter und ihre Wechselwirkungen zu erkennen und damit auch die Ursachen für das Problem zu identifizieren.
Unsicherheitsanalyse untersucht unvermeidbare Streuungen bzw. Unsicherheiten der Parameter. Daraus werden die Streuungen der Zielgrößen analytisch und genau berechnet. Somit ist es möglich, die Variation eines Prozesses an einem Arbeitspunkt für eine Spezifikation zu untersuchen, ob die geforderte Sicherheit und Robustheit des Prozesses gewährleistet wird?
Optimierung sucht im Parameterraum nach dem besten Arbeitspunkt, bei dem die Zielgröße zu den von Nutzer-definierten Anforderungen am besten erfüllt ist. Man muss dabei nur Kriterien formulieren und OptiY ermittelt dann automatisch optimale Parameter. Es ist beispielsweise sinnvoll, einen optimalen Arbeitspunkt für ein Prozess zu finden, bei dem die Energieverlust am geringsten ist.
Robust Design ist eine Optimierung der Unsicherheitsanalyse unter Einbeziehung der Parameterstreuungen bzw. Unsicherheiten. Dabei wird ein optimaler Arbeitspunkt für eine Spezifikation gesucht, bei dem trotz der unvermeidbarer Parameterstreuungen geforderte Sicherheit und Robustheit des Prozesses immer gewährleistet ist. Diese fortschrittliche Technologie gehört zu dem Innovativen Kern von OptiY.
Mit der Data-Mining Edition kann man auch die Daten für die Versuchsplanung generieren. Zu den statistischen Versuchsplanung lassen sich verschiedenen Methoden wie Monte-Carlo, Latin-Hypercube, Sobol, Orthogonal Array, Central Composite usw. einsetzen. Korrelationen zwischen den Parametern oder Bedingungen für die Daten können dabei leicht abgebildet werden. Eine weitere Innovation von OptiY ist die adaptive Versuchsplanung. Auf der Basis eines am Anfang existierenden Datenbestandes wird zuerst ein Metamodell gebildet. Darauf werden gezielt weitere Messpunkte im Parameterraum vorgeschlagen, um genauere Metamodelle bzw. bessere Ergebnisse der Datenanalyse zu erzielen. Es ist die effizientesten Versuchsplanung mit wenigsten Messpunkte. Dadurch spart man viel Aufwand, Zeit und Kosten für teure Versuche.
Fallstudien
